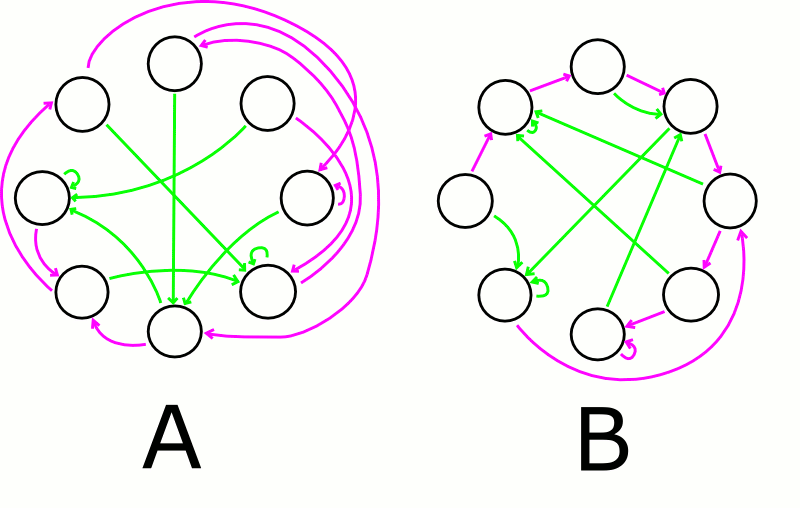
However, A and B have exactly the same structure. The only difference between them is the placement of the black circles. They have the same random pointer structure, but in B the circles are placed to make the purple pointers as sequential as possible.
In random bigraphs, as in the figures above, the complexity is approximately halved when put in a sequence.
This general principle works on most elements of programming languages, such as the order of execution, the definition of class hierarchies, call structures, etc. It also works on data structures and accesses, such as lists, trees, garbage collection, object structures, etc. All these have in common that their structures have multiple references, such as jumps, if-else constructs, general program flow constructs, gotos, function calls, pointers, object references, classes with multiple references and inheritances.
For all these things have the property of the figures:
They can be
made complex or simple, depending on how they are laid out, because
they all have referencing and branching.
This is reflected in principles like Ockhams razor, the K.I.S.S. principle: "Keep It Simple, Stupid!", in Einsteins principle:"It should be as simple as possible, but not simpler", etc.
Simplicity is better for people, but it is also better for theories, math, computer programs, and similar.
The graphs could justs as well have represented program flow, or class hierarchies, or call back structures, or gotos, or state machines, etc. All these structures have in common that there are many ways of representing them, and the simplest ways are quite sequential.
As for LISP, the green pointers can be the CAR, while the purple can be the CDR.
I am referring to a popular programming paradigm which is often confused with object oriented programming: Instead of making programs into a limited set of useful well thought out objects, functions, and structures, the programmers make big nets of inter dependent classes with lots of unnecessary functions.
Splitting up sequential programs into separate methods which are called only once, is an often used method for making the code less sequential.
As you can understand now, this is wrong, because it is unnecessarily complex, which introduces errors, incomprehensibility, obfuscation, and wastes time.
A concept which is somewhat related to this is coupling, which can be low or strong, but this refers more to the number of references than to how random or sequential they are. The examples above have 2 references for each node since this is general, but more references is of course more complexity per node.
(c) Kim Øyhus 2007-06-03